引言
这是每一个程序员都应该无条件掌握的知识!
写在前面的话
在涉及到任何字符编码操作前,得先对字符编码有所了解,要不然只可能是知其然而不知其所以然。
本文属于 字符编码系列文章之一,更多请前往 字符编码系列。
基本概念
字符
各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。 也就是说,它是一个信息单位,一个数字是一个字符,一个文字是一个字符,一个标点符号也是一个字符。
字节
字节是一个8bit的存储单元,取值范围是0x00~0xFF。 根据字符编码的不同,一个字符可以是单个字节的,也可以是多个字节的。
字符集
字符的集合就叫字符集。不同集合支持的字符范围自然也不一样,譬如ASCII只支持英文,GB18030支持中文等等
在字符集中,有一个码表的存在,每一个字符在各自的字符集中对应着一个唯一的码。但是同一个字符在不同字符集中的码是不一样的,譬如字符“中”在Unicode和GB18030中就分别对应着不同的码(20013与54992)。
字符编码
定义字符集中的字符如何编码为特定的二进制数,以便在计算机中存储。 字符集和字符编码一般一一对应(有例外)
譬如GB18030既可以代表字符集,也可以代表对应的字符编码,它为了兼容ASCII码,编码方式为code大于255的采用两位字节(或4字节)来代表一个字符,否则就是兼容模式,一个字节代表一个字符。(简单一点理解,将它认为是现在用的的中文编码就行了)
字符集与字符编码的一个例外就是Unicode字符集,它有多种编码实现(UTF-8,UTF-16,UTF-32等)
简要介绍
下面举些示例方便快速理解。
字符集与字符编码的快速区分
-
ASCII码是一个字符集,同时它的实现也只有一种,因此它也可以指代这个字符集对应的字符编码
-
GB18030是一个字符集,主要是中国人为了解决中文而发明制定的,由于它的实现也只有一种,所以它也可以指代这个字符集对应的字符编码
-
Unicode是一个字符集,为了解决不同字符集码表不一致而推出的,统一了所有字符对应的码,因此在这个规范下,所有字符对应的码都是一致的(统一码),但是统一码只规定了字符与码表的一一对应关系,却没有规定该如何实现,因此这个字符集有多种实现方式(UTF-8,UTF-18,UTF-32),因此这些实现就是对应的字符编码。 也就是说,Unicode统一约定了字符与码表直接一一对应的关系,而UTF-8是Unicode字符集的一种字符编码实现方式,它规定了字符该如何编码成二进制,存储在计算机中。
字符集与字符编码发展简史
这段资料主要借鉴了参考链接中的描述,只对大概发展做一个简要概述,每一个编码的详细介绍请参考系列文章目录里的其它文章。
欧美的单字节字符编码发展
-
美国人发明了计算机,使用的是英文,所以一开始就设计了一个几乎只支持英文的字符集
ASCII码(1963 发布),有128个码位,用一个字节即可表示,范围为00000000-01111111 -
后来发现码位不够,于是在这基础上进行拓展,256个字符,取名为
EASCII(Extended ASCII),也能一个字节表示,范围为00000000-11111111 -
后来传入欧洲,发现这个标准并不适用于一些欧洲语言,于是在
ASCII(最原始的ASCII)的基础上拓展,形成了ISO-8859标准(国际标准,1998年发布),跟EASCII类似,兼容ASCII。然后,根据欧洲语言的复杂特性,结合各自的地区语言形成了N个子标准,ISO-8859-1、ISO-8859-2、...。 兼容性简直令人发指。
亚洲,只能双字节了
- 计算机传入亚洲后,国际标准已被完全不够用,东亚语言随便一句话就已经超出范围了,也是这时候亚洲各个国家根据自己的地区特色,有发明了自己地图适用的字符集与编码,譬如中国大陆的GB2312,中国台湾的BIG5,日本的Shift JIS等等 这些编码都是用双字节来进行存储,它们对外有一个统称(ANSI-American National Standards Institute),也就是说GB2312或BIG5等都是ANSI在各自地区的不同标准。
Unicode,一统天下
-
到了全球互联网时代,不同国家,不同地区需要进行交互,这时候由于各自编码标准都不一样,彼此之间都是乱码,无法良好的沟通交流,于是这时候ISO组织与统一码联盟分别推出了UCS(Universal Multiple-Octet Coded Character Set)与Unicode。后来,两者意识到没有必要用两套字符集,于是进行了一次整合,到了Unicode2.0时代,Nnicode的编码和UCS的编码都基本一致(所以后续为了简便会同意用Unicode指代),这时候所有的字符都可以采用同一个字符集,有着相同的编码,可以愉快的进行交流了。
-
需要注意的是UCS标准有自己的格式,如UCS-2(双字节),UCS-4(四字节)等等 而Unicode也有自己的不同编码实现,如UTF-8,UTF-16,UTF-32等等 其中UTF-16可以认为是UCS-2的拓展,UTF-32可以认为是UCS-4的拓展,而Unicode可以认为是Unicode最终用来制霸互联网的一种编码格式。
在中国,GB系列的发展
-
在计算机传入中国后,1980年,中国国家标准总局发布了第一个汉字编码国家标准GB2312(2312是标准序号),采用双字节编码,里面包括了大部分汉字,拉丁字母,日文假名以及全角字符等。
-
然而,随着程序的发展,逐渐发现GB2312已经不满足需求了,于是1993年又推出了一个GBK编码(汉字国标扩展码),完全兼容GB2312标准。并且包括了BIG5的所有汉字,与1995年发布。 同时GBK也涵盖了Unicode所有CJK汉字,所以也可以和Unicode做一一对应。
-
后来到了2000年,又推出了一个全新的标准 GB 18030,它不仅拓展了新的字符,如支持中国少数名族文字等,而且它采用了单字节,双字节,四字节三种编码方式,所以完全兼容ASCII码与GBK码。 到了2005年,这一标准有进行了拓展,推出了GB18030-2005,剧本涵盖所有汉字,也就是说,现在使用的国标标准码就是GB18030-2005了。
不同字符编码的字符是如何进行转换的
-
如果是相同字符集,由于相同字符集中的码都是一样的,所以只需要针对不同的编码方式转变而已。譬如UTF-16转UTF-8,首先会取到当前需要转换的字符的Unicode码,然后将当前的编码方式由双字节(有4字节的拓展就不赘述了),变为变长的1,2,3等字节
-
如果是不同的字符集,由于不同字符集的码是不一样的,所以需要各自的码表才能进行转换。譬如UTF-16转GBK,首先需要取到当前需要转换的字符的Unicode码,然后根据Unicode和GBK码表一一对应的关系(只有部分共同都有的字符才能在码表中查到),找到它对应的GBK码,然后用GBK的编码方式(双字节)进行编码
编年史
注意,此编年史引用自来源链接中的内容(做了部分修改与更新)-http://www.jianshu.com/p/bd7a6c508c33
-
ASCII 1960 开发 1963 发布 1986 最后一次更新
-
ISO-8859-1 1998 发布
-
GB2312 1980 发布
-
GBK 1993 发布
-
GB18030 2000年3月17日发布 GB18030-2000 2001年的1月强制执行GB18030-2000 2005年发布GB18030-2005
-
UCS与Unicode 1984年 UCS开始制定标准 1991年10月 Unicode1.0发布 1992年1月 Unicode与ISO 10646国际编码标准正式合作,发展一套通用 编码标准 1993年 ISO组织发表UCS(标准编号ISO 10646)国际编码标准的第一个版 本 1993年6月 修订了Unicode 1.0,发布Unicode 1.1 1996 年7月 发布Unicode2.0(实现了代理机制(UTF-16),这时候Unicode和UCS可以近似认为一样
-
UTF-16 1996年7月 发布
-
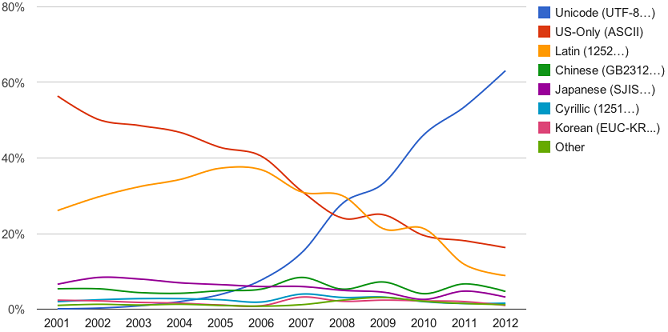
UTF-8 1993 发布 1996年 微软的CAB(MS Cabinet)在UTF-8标准正式落实前就明确容许在任何地方使用UTF-8编码系统 2008 流行
UTF-8制霸互联网过程